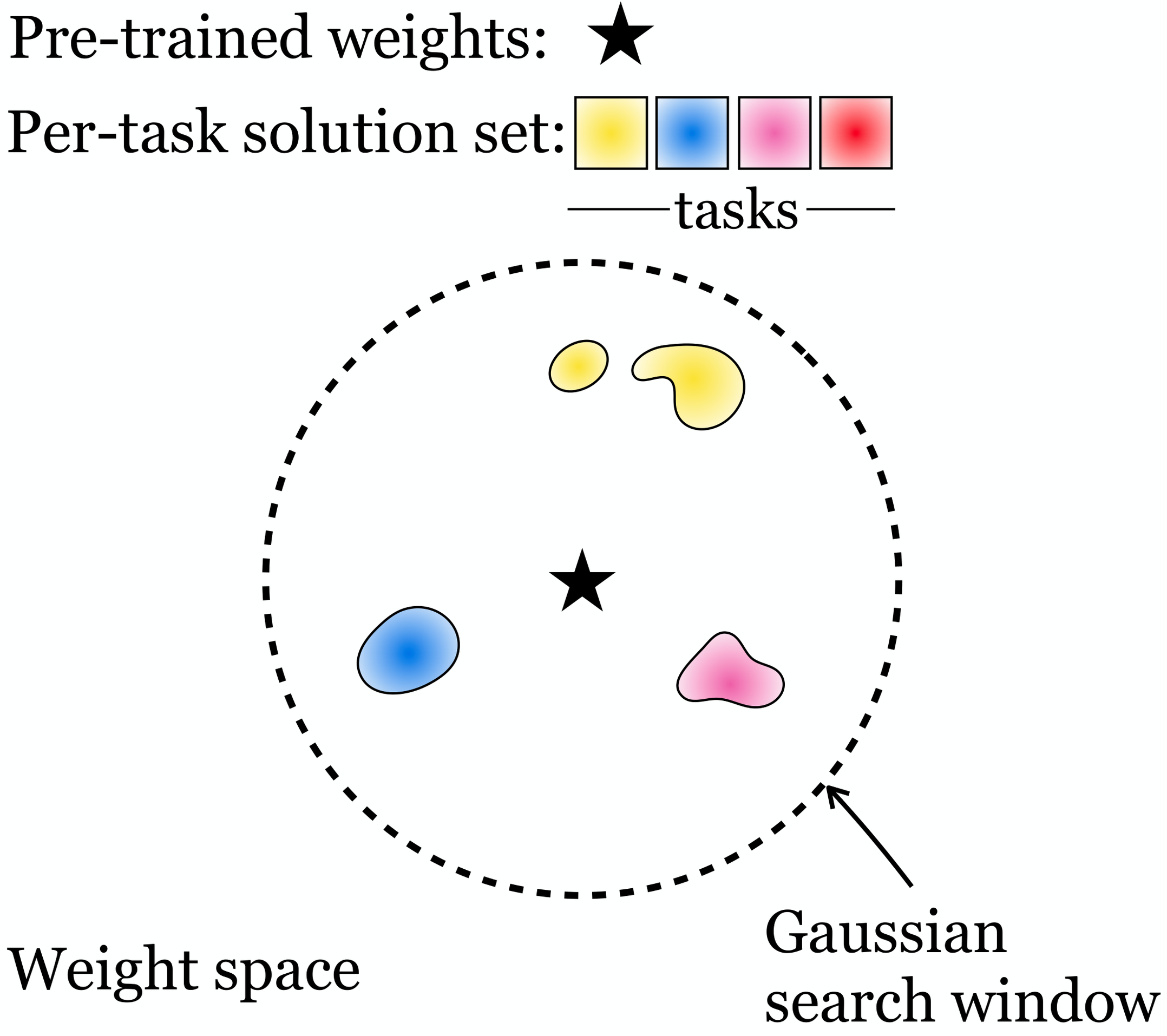
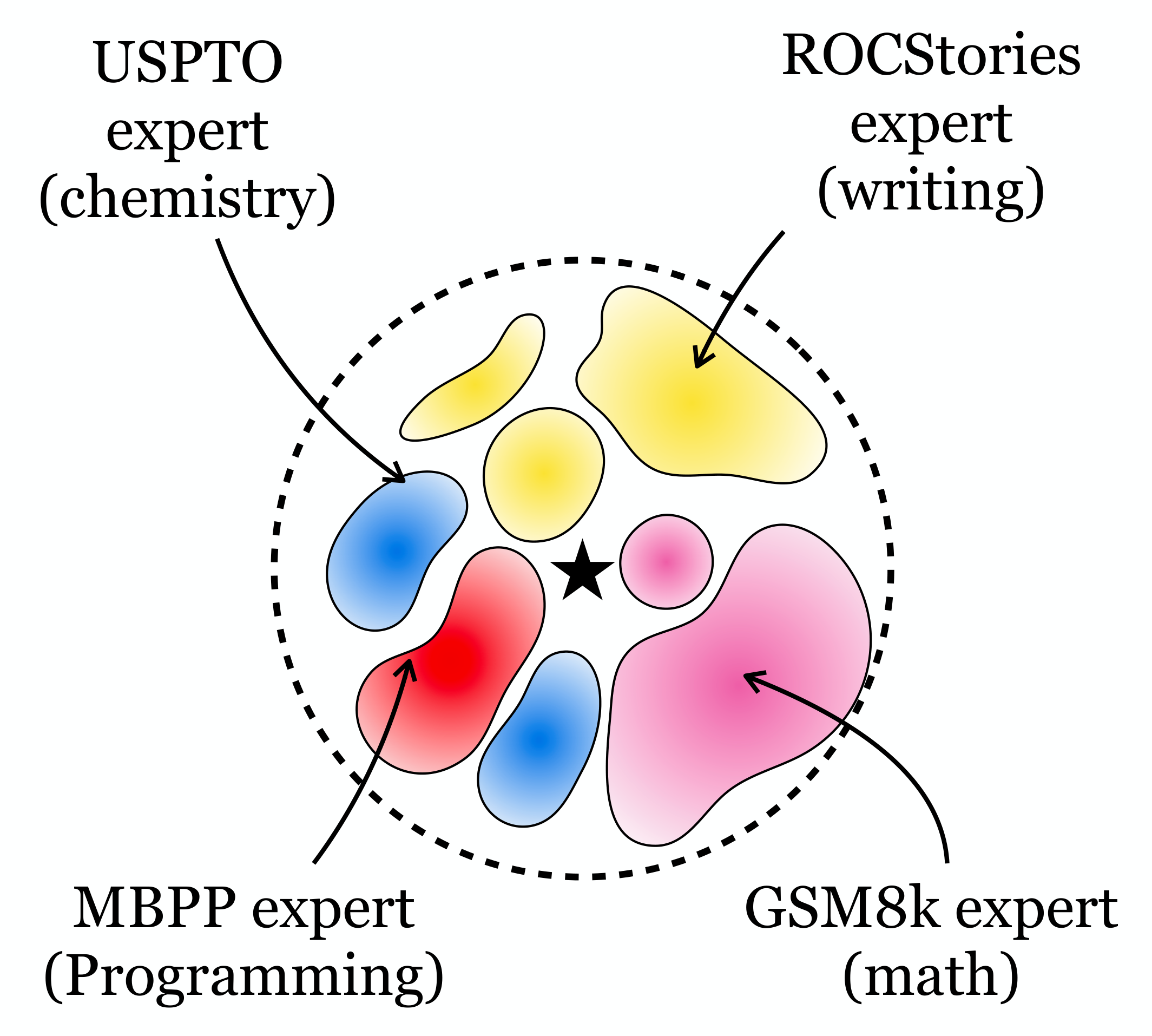
Diverse Task Experts Are Dense Around Pretrained Weights
Massachusetts Institute of Technology


Note: the two figures above are generated by Gemini
Core finding: The neighborhood around pretrained weights already contains task-specific experts. In small models they are sparse and hard to find; in large models they are dense and easy to discover.
This motivates a simple post-training algorithm we call RandOpt: sample N weight vectors, keep the top K, and majority vote at inference time.
Click either figure to see the accuracy landscape